Best practices for multiple teams deploying to the same Oracle database
Last updated: July 14, 2025
This document discusses use cases when multiple teams deploy to the same database. We will discuss the following two use-cases in this scenario:
Each team has one or more dedicated schemas in the same database
Multiple teams write to one or more shared schemas in the same database
Use-case 1: Each team has one or more dedicated schemas in the same database
This is a common use case for applications that integrate multiple subsystems. Multiple teams, each with its own Git repository, deploy database changes into their own dedicated schemas in the same database.
Team | Schema |
|---|---|
Team 1 | SchemaA |
Team 2 | SchemaB |
Team 3 | SchemaC |
Team 4 | SchemaD |
Structuring your Git repository
Each team will dedicate a directory in their repository for database changes. In this directory, they can manage all their scripts along with the changelog.xml file. The team can also create a directory for their schema.
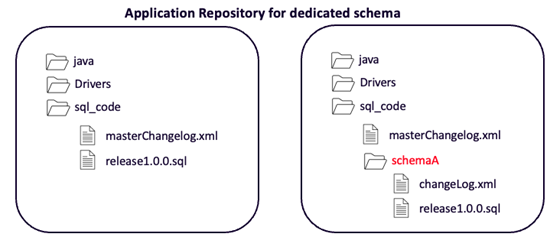
In the case of a team deploying to multiple schemas, they could organize their repository so that they have a subdirectory for each schema.
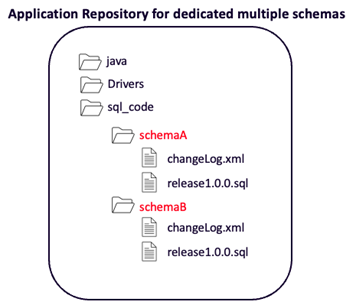
The team needs a main changelog file which can control the flow of all changes to all schemas.
See the section "Deploying with Liquibase" later in this document for sample scripts.
Use-case 2: Multiple teams write to one or more shared schemas in the same database
In this use case, multiple teams, each with their own Git repository, deploy database changes to one or more shared schemas. This use case is common for legacy applications that have added subsystems over time or other complex application architectures.
The team needs a main changelog file that controls the flow of all changes to all schemas.
See the "Deploying with Liquibase" section later in this document for sample scripts.
Use-case 2: Multiple teams write to one or more shared schemas in the same database
In this use case, multiple teams, each with their own Git repository, deploy database changes to one or more shared schemas. This use case is typical for legacy applications that have added subsystems or other complex application architectures over time.
Team | Schema |
|---|---|
Team 1 | SchemaA, SchemaB, SchemaC |
Team 2 | SchemaA, SchemaB, SchemaC |
Team 3 | SchemaA, SchemaB, SchemaC |
Team 4 | SchemaA, SchemaB, SchemaC |
You will use a single URL and credentials to connect to all databases, requiring you to use a single service account with permissions to multiple databases.
Within SQL scripts, each object must be fully qualified with the database name, schema name, and object name. This is a requirement because a single service account is used to deploy to multiple databases.
Liquibase tracking tables (
DATABASECHANGELOGandDATABASECHANGELOGA sing rackdeplomentstomultp) will be created only in one database that is specified in the URL. A single tracking table will track dependents and multiple databases in the database specified in the URL.
Note: It is important to understand that teams must communicate with each other about their database changes going into shared schemas. Database changes often have dependencies, which need to be coordinated to be deployed in the correct order.
Structuring your Git repository
When multiple teams share common schemas, it is not possible to use each team's own application repository. This use case requires setting up a dedicated SQL repository for shared schemas.

The team needs a main changelog file that can control the flow of all changes to all schemas.
See the "Deploying with Liquibase" section later in this document for sample scripts.
Sample mainChangelog.xml for multi-schema repository
Deploying with Liquibase using a single service account to deploy to multiple shared schemas
# add liquibase path to the environment variable
export PATH=<Path to Liquibase>:${PATH}
# git clone or retrieve a versioned artifact
git clone <GIT URL to the repo>
cd <Repo>/sql_code
# run the "status" command
liquibase status --changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password> \
-–verbose
# run the "update" command
liquibase update --changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password>
# run the "history" command
liquibase history --changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password>Deploying with Liquibase using proxy users to deploy to one schema
# add liquibase path to the environment variable
export PATH=<Path to Liquibase>:${PATH}
# git clone or retrieve a versioned artifact
git clone <GIT URL to the repo>
cd <Repo>/sql_code
LBSCHEMANAMES="${1:-"HR OC OE SH"}"
for LBSCHEMA in $LBSCHEMANAMES
do
# run the "status" command
liquibase status --changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password> \
--default-schema-name=${LBSCHEMA} \
–-verbose
# run the "update" command
liquibase update –-changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password> \
--default-schema-name=${LBSCHEMA}
# run the "history" command
liquibase history --changelog-file=masterChangelog.xml \
--url=<Database URL> \
--username=<username> \
--password=<password> \
--default-schema-name=${LBSCHEMA}
doneLiquibase automatically creates DATABASECHANGELOG and DATABASECHANGELOGLOCK tables (also called DBCL tables) for tracking deployments. These tables are created in the default schema for the user connecting to the database.
If you want your DBCL tables to be created in another schema, e.g., a dedicated schema for Liquibase tracking only, then you can use --liquibase-schema-name=<schema> to indicate your specific schema. You need to make sure that the service account allows creating DBCL tables in this schema and allows querying these tables.
--liquibase-schema-name=<schema>:The parameter specifies the schema to use for creating Liquibase objects, such as the DATABASECHANGELOG and DATABASECHANGELOGLOCK tracking tables.--default-schema-name=<schema>:The parameter specifies the default schema name to use for the database connection.